
Published by

Sylvia Cheng, PhD
Research Engineer (Berkeley PhD)

Daniel Fleury
Founding Technical Staff (CS & Cognitive Science @ Johns Hopkins)
We report early findings that physicians can work with a clinical agent, “Cortex,” to coordinate full loops of asynchronous primary care. Across 1,678 suggested care actions — spanning prescriptions, lab orders, and follow-up messages — generated for 244 patients with distinct problem profiles, clinicians approved 98% of proposals that reached a final non-pending verdict. This points to a practical model for collaborative care: tool-using clinical agents can maintain longitudinal problem context across the patient chart and conversation history, then precompute care actions for physicians to review, revise, and execute.
This analysis evaluates how clinicians responded to AI-suggested actions in a real care workflow at Lotus AI. Unlike evaluations centered on simulated encounters, benchmark questions, or ratings of generated text, the unit of evaluation here is a proposed action: something that could be sent to a patient, ordered, prescribed, revised, or rejected by a clinician.
Across all proposed actions, 66.7% were approved, 2.8% were rejected, and 30.5% remained pending. The low rejection rate suggests that clinicians rarely found Cortex’s proposed actions inappropriate enough to reject outright. The substantial pending rate suggests that the main operational challenge is not only clinical correctness, but workflow closure: ensuring that the right proposal reaches the right clinician with enough context to support a timely decision.
Highlights
Across 1,678 suggested care actions, 66.7% were approved, 2.8% were rejected, and 30.5% remained pending. Among actions with final non-pending verdicts, 98% were approved.
Follow-up messages were the most consistently accepted action type, with a 68.0% approval rate and 1.3% rejection rate.
Prescriptions had the highest rejection rate at 10.2%, reflecting the greater safety, regulatory, and clinical-context burden of medication decisions.
Lab orders showed evidence of improvement through iteration. More revision cycles were significantly associated with higher approval rates for lab orders: Spearman ρ = 0.20, p < 0.001.
Approval was stable across revisions. Actions with a prior approval were re-approved 98.6% of the time.
Approved actions reached final approval in a median of 7.6 hours, consistent with same-day or next-day asynchronous review.
High-action patients were geographically distributed across 74 California cities and ranged from 20 to 82 years old.
High-action users primarily discussed medical appointments, medication management, and mental health support, which together accounted for more than half of classified messages.
Background
Asynchronous telemedicine is a mode of care in which patients and clinicians exchange information without needing to communicate at the same time. The U.S. Health Resources and Services Administration describes asynchronous telehealth as allowing providers and patients to share information at different times, with common uses including patient intake, follow-up care, secure text updates, images, medical reports, lab results, and health histories.[1] A systematic review similarly defines asynchronous telemedicine as telemedical interaction in which neither the patient nor provider is communicating simultaneously.[2]
This model is relevant because access to timely care remains constrained. A 2025 AMN Healthcare survey found that the average time to schedule a new patient physician appointment in 15 large U.S. metropolitan areas was 31 days, up from 26 days in 2022 and 21 days in 2004. For family medicine, the average wait was 23.5 days.[3]
At Lotus AI, care often begins synchronously. A patient talks with Lotus AI in chat, describes a concern, reviews imported health information, or requests a clinical action. When the request may require physician involvement, the case moves into an asynchronous clinical workflow. In this workflow, Cortex helps prepare the next step for clinician review.
This is an important distinction. The AI system is not only answering the patient. It is helping coordinate care.
Many evaluations of medical AI focus on whether a model can produce an accurate answer, generate a differential diagnosis, summarize a chart, or perform well on a benchmark. These evaluations remain important, but they do not fully capture whether an AI system can participate usefully in care delivery. A randomized clinical trial in JAMA Network Open found that providing physicians access to a large language model did not significantly improve diagnostic reasoning performance compared with conventional resources, despite broader evidence that LLMs can perform well on some clinical tasks.[4] More recent work has also argued that traditional benchmarks can miss important gaps in end-to-end clinical reasoning, including differential diagnosis and navigating uncertainty.[5]
For asynchronous primary care, a practical evaluation question is:
When an AI system suggests a concrete care action, does the clinician agree?
This analysis studies that question directly.
The Cortex action workflow
Lotus AI combines patient-facing AI interaction with clinician-supervised asynchronous care.
Patients can use Lotus AI to ask questions, describe symptoms, review health information, or request clinical support. In some cases, the request is informational and can be addressed in chat. In other cases, the request may require physician review, such as a lab order, prescription, or formal follow-up.
For example, a patient might make a direct request:
“Can you refill my current insulin dose?”
Another patient might describe a more ambiguous but clinically concerning symptom pattern:
“Hi, not sure who to ask about this, but I’ve had a headache most of the day and I’m acting kind of weird honestly. I dropped my phone twice and I feel a little clumsy on one side, like my hand isn’t working totally right. My partner said my speech sounded off for a minute earlier but I think I’m okay now. I also feel kind of dizzy and my vision got blurry for a bit. I was going to just sleep it off, but it’s making me nervous.”
In both cases, the system can route the encounter for clinician review. Background agents summarize the patient’s concern, reconcile it against the available chart and conversation history, and generate problem-oriented context for downstream review.
Cortex is the clinician-facing agent in this workflow. It synthesizes available patient context, including chart history, recent conversation content, prior care activity, and relevant clinical information. It then generates proposed actions for physician review.
The three action types studied here were:
Action type | What Cortex suggests |
|---|---|
Follow-up messages | Drafted patient communications based on clinical context |
Lab orders | Prepared lab orders for clinician review |
Prescriptions | Drafted prescriptions for clinician review before submission |
Each proposed action can be approved, rejected, revised, or left pending. Physicians can also interact with Cortex to revise proposed actions before execution.
This design keeps clinicians in control of final clinical decisions while allowing the agent system to prepare structured next steps. Cortex does not replace clinical judgment; it prepares work for clinical judgment.
Study cohort and action volume
The analysis included 1,678 Cortex-suggested actions across 244 patients.
Across patients, the median number of unique proposed actions was 5, with a mean of 6.9. The distribution was right-skewed. Most patients had fewer than 10 proposed actions, while a smaller number had substantially higher action volume, including some with more than 70 proposed actions.
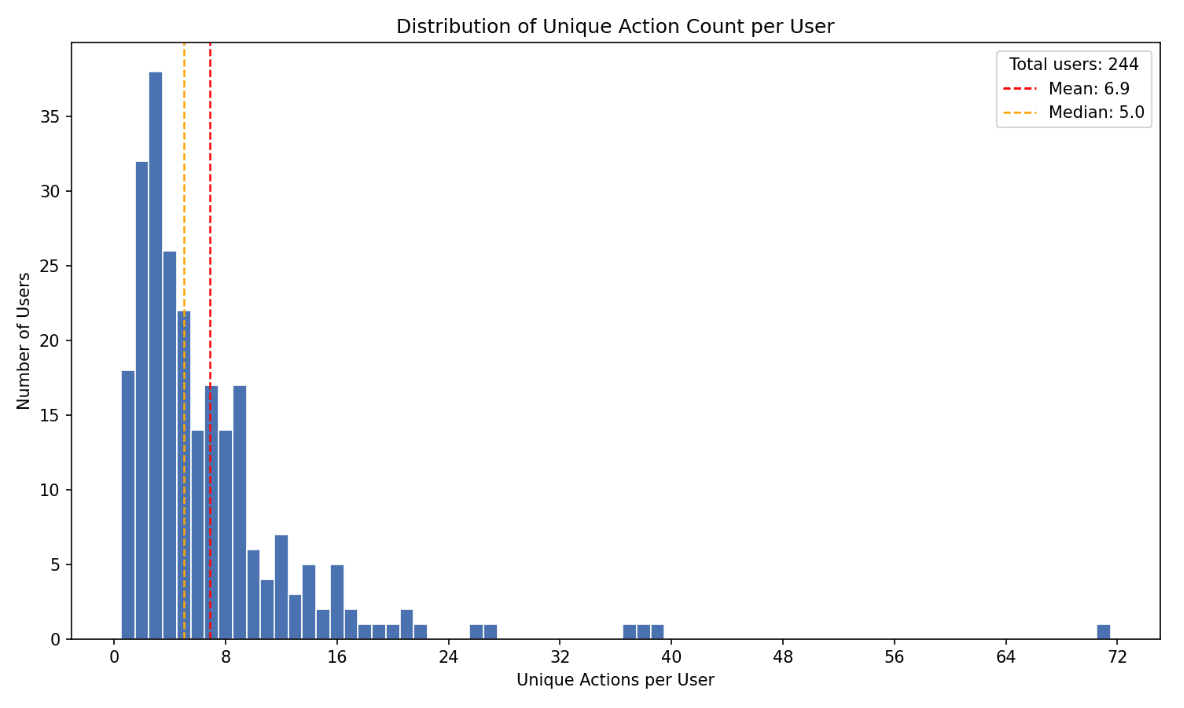
This pattern is consistent with longitudinal primary care use. Many patients interact with the system for discrete needs. A smaller group generates ongoing care coordination around medications, labs, symptoms, follow-up, and administrative tasks.
The right tail is particularly important for evaluating clinical agents. High-action users create a harder test of continuity: the system must maintain context across repeated interactions, evolving problems, and multiple possible next steps.
For subsequent demographic and conversation-topic analyses, we focused on 108 high-action users with more than five unique proposed actions.
Clinician decisions on suggested actions
Across all 1,678 suggested actions, 66.7% were approved, 2.8% were rejected, and 30.5% remained pending.
Action type | Approved | Rejected | Pending | n |
|---|---|---|---|---|
All actions | 66.7% | 2.8% | 30.5% | 1,678 |
Follow-up messages | 68.0% | 1.3% | 30.6% | 901 |
Prescriptions | 65.3% | 10.2% | 24.4% | 225 |
Lab orders | 65.2% | 2.2% | 32.6% | 552 |
The low rejection rate is notable. In this workflow, rejection is the clearest signal that a clinician reviewed an AI-suggested action and decided it should not be executed. Across all actions, this occurred in fewer than 3% of cases.
Pending actions require a different interpretation. A pending action is not necessarily a rejected action. It may reflect physician workload, unresolved prerequisites, lower urgency, the need for additional information, or a proposal that became stale before review. In some cases, pending may also function as an implicit non-action state when clinicians disagree but do not actively reject.
For this reason, we report both the overall approval rate and the approval rate among finalized non-pending decisions. Among actions that reached a final approve-or-reject verdict, clinicians approved 98%.
Follow-up messages were the most consistently accepted action type
Follow-up messages were Cortex’s strongest action type. Clinicians approved 68.0% and rejected only 1.3%.
This action type appears well suited to AI-assisted primary care. Follow-up messages often involve asking for missing information, checking symptom status, monitoring medication response, clarifying instructions, or closing the loop after a clinical decision.
These tasks are clinically meaningful but generally lower risk than prescribing or ordering diagnostics. They also map naturally to asynchronous care, where patient communication is often the mechanism by which care continues between formal encounters.
In this dataset, follow-up messages also had the highest downstream execution success rate at 45.8%. This suggests that Cortex was not only drafting messages clinicians accepted, but also supporting an action type that could more reliably move through the operational workflow.
Prescriptions carried the highest review burden
Prescriptions had a 65.3% approval rate and a 10.2% rejection rate. This was the highest rejection rate among the three action types.
The result is expected given the risk profile of medication decisions. Prescribing often depends on context that may not be fully available to an agent, including physical examination findings, recent vitals, pregnancy or reproductive history, contraindications, current adherence, pharmacy constraints, controlled-substance rules, specialist involvement, and confirmatory labs.
Prescription rejection does not necessarily indicate that the proposed medication was implausible. In many cases, the issue was that the clinical foundation was incomplete. A medication might be reasonable after an exam, after laboratory confirmation, after specialist review, or after additional patient information. But it may not be appropriate to prescribe yet.
This distinction matters for clinical agent design. The prescription task is not only to know what medication might fit the problem. It is to know when prescribing is premature.
Lab orders showed evidence of improvement through iteration
Lab orders had a 65.2% approval rate and a 2.2% rejection rate.
Their most interesting feature was the relationship between revision and approval. Lab orders were the only action type where more revision cycles were statistically associated with higher approval rates: Spearman ρ = 0.20, p < 0.001.
This suggests that lab-order proposals may benefit from iterative refinement. Lab ordering often requires aligning the patient’s symptoms, chronic conditions, prior results, preventive care gaps, administrative readiness, and the clinician’s judgment about whether a result would change management.
In practice, an initial lab proposal may be directionally reasonable but incomplete. A revised proposal can become more targeted, better justified, or better aligned with physician intent.
This is one of the clearer signals of collaborative value in the dataset. Cortex is not only producing static suggestions for clinicians to accept or reject. For lab orders, the proposal appears to improve as the clinician-agent loop continues.
Approval was stable across revisions
We examined whether prior clinician decisions predicted subsequent approval.
Prior decision state | Approval rate | n |
|---|---|---|
Previously approved | 98.6% | 786 |
Previously pending | 66.5% | 519 |
No prior decision / first event | 0.0% | 365 |
Previously rejected | 0.0% | 8 |
Actions with a prior approval were re-approved 98.6% of the time.
This suggests that once an action reached a clinically acceptable direction, subsequent versions usually remained acceptable. That may reflect minor updates to already-approved proposals, stability in the underlying clinical rationale, or the agent’s ability to preserve the clinician-approved plan as new information arrives.
Future analyses should distinguish between small revisions and major revisions. A wording update to a follow-up message is different from a material change to a medication or lab panel. Still, the observed stability suggests that approval is not fragile across the action lifecycle.
Execution differed by action type
Clinician approval is not the same as downstream execution.
After approval, an action still has to complete in the real world. A message must be delivered. A prescription must pass through prescribing infrastructure and pharmacy constraints. A lab order may require complete demographics, insurance compatibility, lab availability, patient scheduling, and successful patient follow-through.
Execution success differed significantly across action types (p < 0.001).
Action type | Execution success rate |
|---|---|
Follow-up messages | 45.8% |
Prescriptions | 39.1% |
Lab orders | 22.5% |
Follow-up messages executed most reliably. Lab orders executed least reliably.
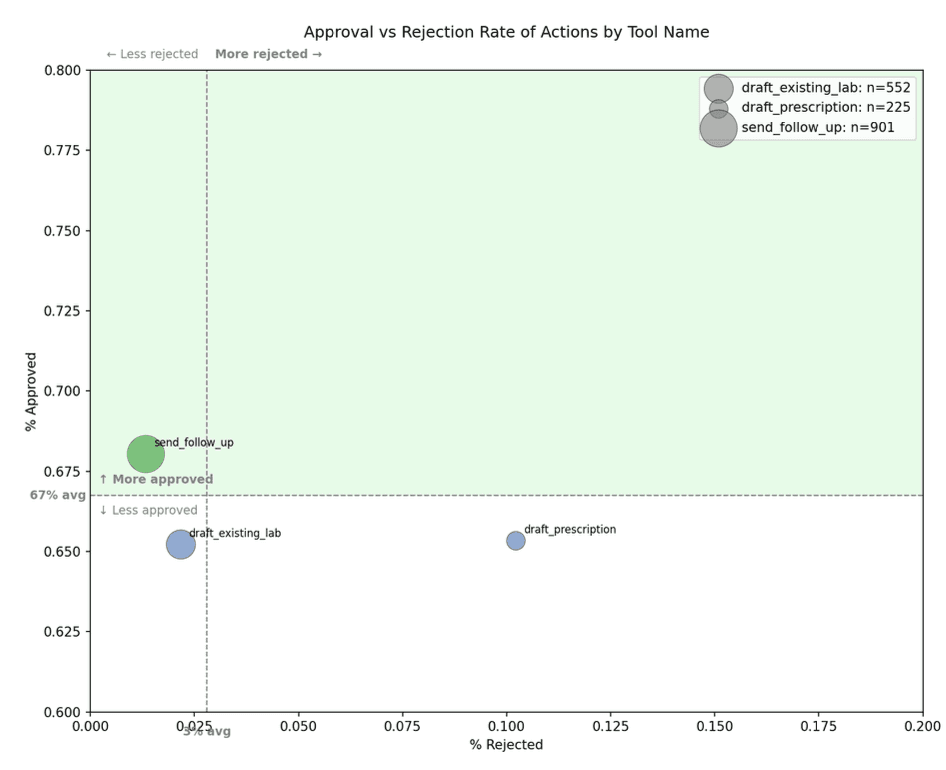
This difference likely reflects the complexity of the operational environment. Sending a follow-up message is primarily a digital communication task. Completing a lab order crosses into administrative and physical-world dependencies.
These findings distinguish two forms of performance: whether a clinician agrees with the proposed action, and whether the care system can complete that action once approved.
For clinical agents, both matter. A clinically appropriate proposal that cannot be executed still leaves the patient without completed care.
Why clinicians rejected suggested actions
Raw rejection rates indicate how often clinicians disagreed with Cortex. Rejection justifications help explain why.
We reviewed clinician-written justifications for rejected actions across prescriptions, lab orders, and follow-up messages.
Prescription rejections
Prescription rejections clustered around five recurring themes.
Need for in-person evaluation.
Clinicians rejected medication proposals when a physical examination, urgent care visit, neurological assessment, or other direct evaluation was needed before treatment.
Need for confirmatory testing.
Some prescriptions depended on missing laboratory or diagnostic confirmation, such as B12 levels, anemia evaluation, or vitamin D status.
Safety concerns or contraindications.
Some proposals were rejected because patient-specific risk factors changed the risk-benefit profile, such as blood pressure instability or elevated vascular risk.
Need for specialist input.
Some medication decisions were considered outside the scope of routine asynchronous primary care and required specialist involvement, such as maternal-fetal medicine, gastroenterology, or neurology.
Over-the-counter availability.
A small number of proposals involved treatments that did not require a prescription.
Lab order rejections
Lab order rejections centered on three themes.
Administrative barriers.
Some patients had missing or outdated insurance, incomplete demographics, or other prerequisites that prevented ordering.
Need for specialist evaluation.
Clinicians deferred some workups to specialists when the testing decision was part of a more complex diagnostic pathway.
Not clinically indicated.
Some proposed labs were redundant, unnecessary, or unlikely to change management.
Follow-up message rejections
Follow-up message rejections were uncommon and generally pragmatic.
Duplicate or redundant outreach.
The same follow-up was already being handled elsewhere.
Patient declined.
The patient had explicitly asked not to receive the proposed communication.
Clinical context changed.
A referral, medication update, new message, or other change made the original follow-up obsolete.
Across action types, rejection was usually about missing context, changed context, administrative constraints, or scope boundaries. These are useful design signals. They point toward better prerequisite checks, stronger stale-action detection, more explicit scope rules, and clearer routing when specialist or in-person evaluation is needed.
High-action patient cohort
To better understand the population driving Cortex activity, we profiled the 108 users with more than five unique proposed actions. This group accounted for the majority of clinician-agent interactions.
The high-action cohort ranged from 20 to 82 years old, with a mean age of 43.2 and a median age of 42.0. Male users represented 55.1% of the cohort, female users represented 33.6%, and the remaining users had unspecified gender.
Before April 3, 2026, Lotus AI availability was concentrated in California. Among high-action users with address data, 102 of 107 were located in California. These users were distributed across 74 cities.
The top 10 cities by user count were:
City | Users |
|---|---|
Los Angeles | 11 |
San Francisco | 6 |
Sacramento | 4 |
San Diego | 4 |
San Jose | 3 |
Yuba City | 2 |
Oakland | 2 |
Lake Elsinore | 2 |
Hermosa Beach | 2 |
Fresno | 2 |
Los Angeles and San Francisco accounted for 17% of the high-action cohort. The remaining users were distributed across large metropolitan areas, suburbs, and smaller communities.
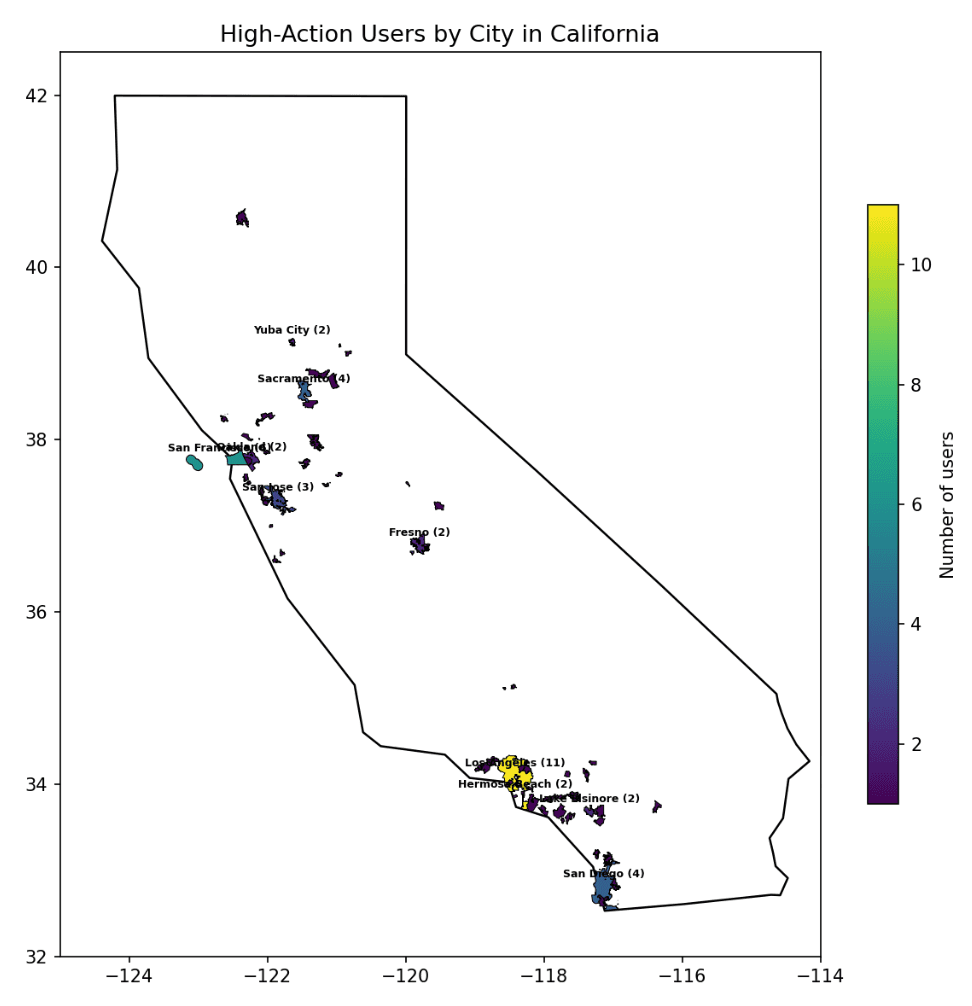
The cohort was not large enough to support strong demographic generalization. However, it does show that high-action use was not limited to a single city or narrow age band.
What high-action users talked about
To understand what drove higher action volume, we classified 23,267 conversation messages from the 108 high-action users into topic categories using LLM-based classification.
The three largest categories were:
Medical appointments
Medication management
Mental health support
Together, these accounted for roughly 54% of all classified messages.
A second tier included dietary recommendations, symptom tracking, gastrointestinal issues, and pain management. Lower-volume categories included exercise modifications, family health history, and stress management.
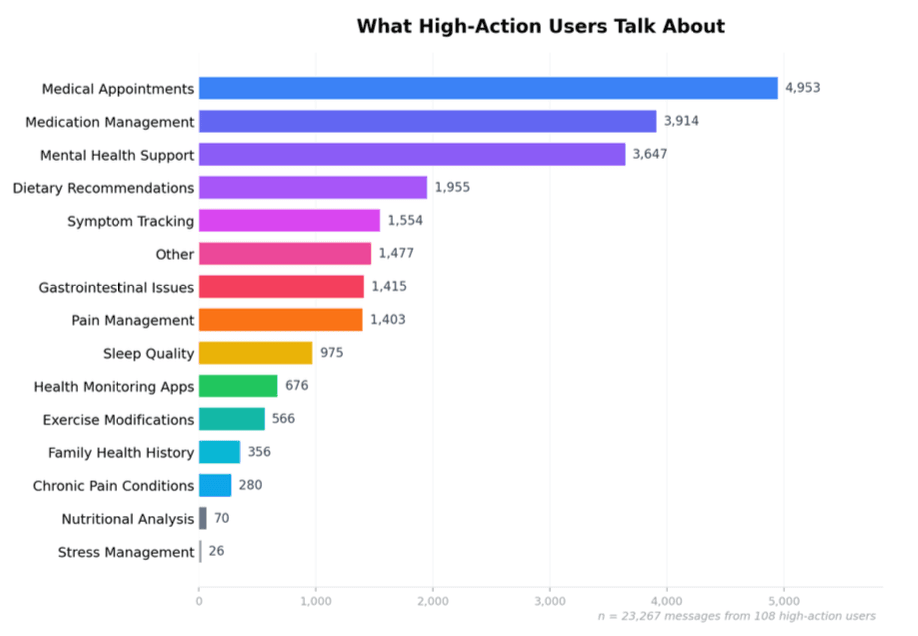
This distribution suggests that high-action users were primarily engaging around care coordination and ongoing condition management. They were not only asking general health questions. They were frequently using Lotus AI for the operational work of primary care: appointments, medications, symptoms, follow-up, and mental health support.
The topic distribution also aligns with Cortex’s proposed action types. Users who frequently discussed medication management, appointments, symptoms, and mental health were also the users most likely to generate follow-up messages, lab orders, and prescription proposals for clinician review.
Time to final decision
We measured the time between an action’s first event and its final event.
Decision group | Median time | n |
|---|---|---|
All actions | 4.3 hours | 1,268 |
Approved actions | 7.6 hours | 848 |
Approved actions reached final approval in a median of 7.6 hours.
Among approved actions, prescriptions resolved fastest, followed by follow-up messages and lab orders.
Approved action type | Median | 80th percentile | n |
|---|---|---|---|
All approved | 7.6 h | 24.0 h | 848 |
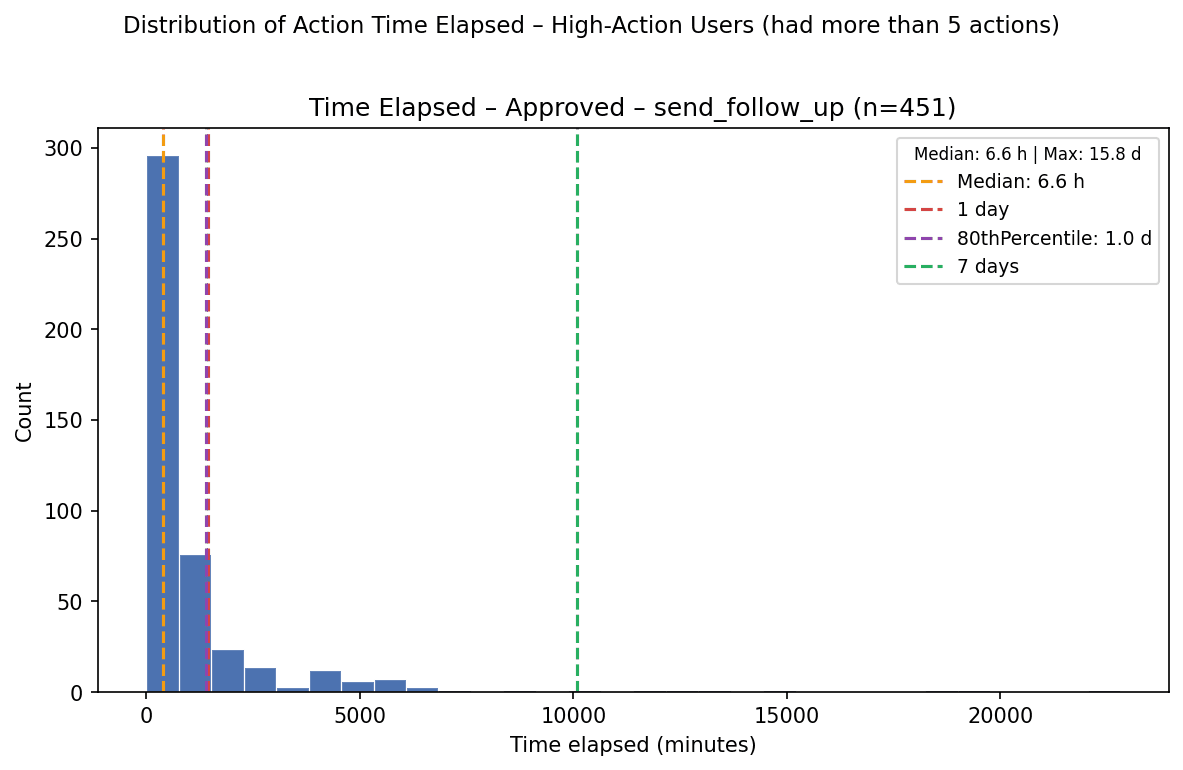
Follow-up messages | 6.6 h | 23.4 h | 451 |
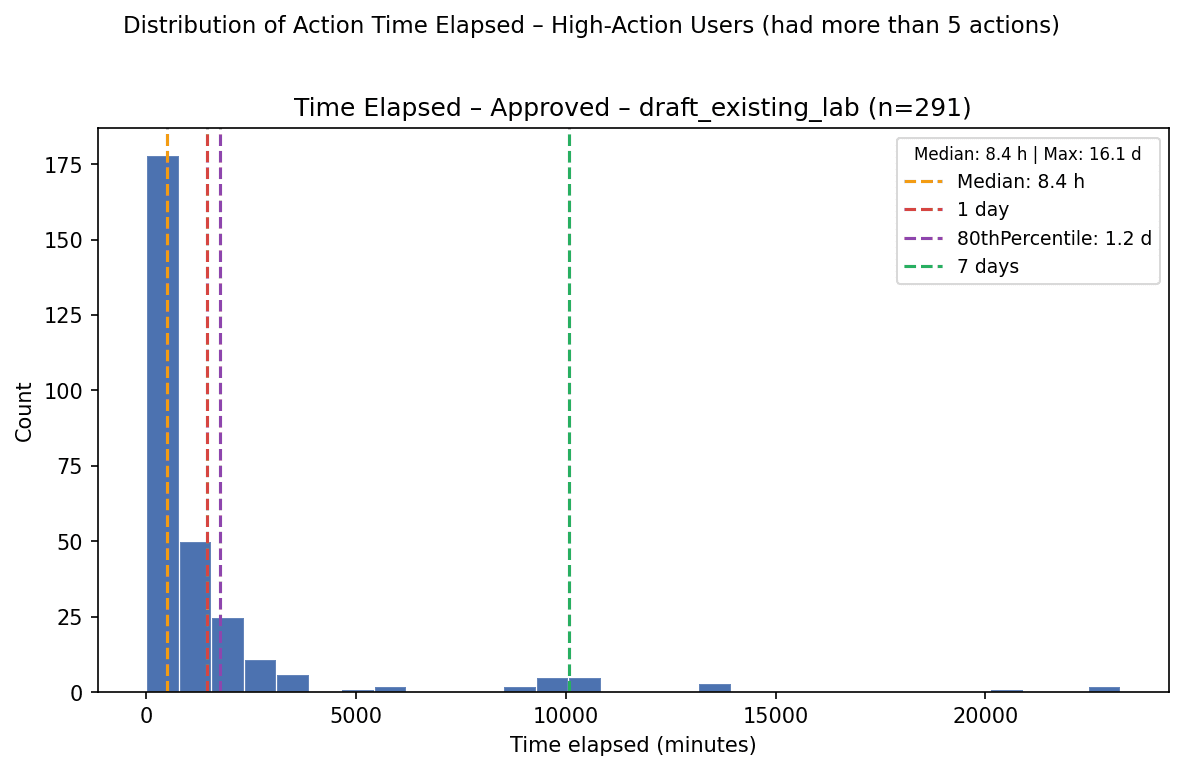
Lab orders | 8.4 h | 29.2 h | 291 |
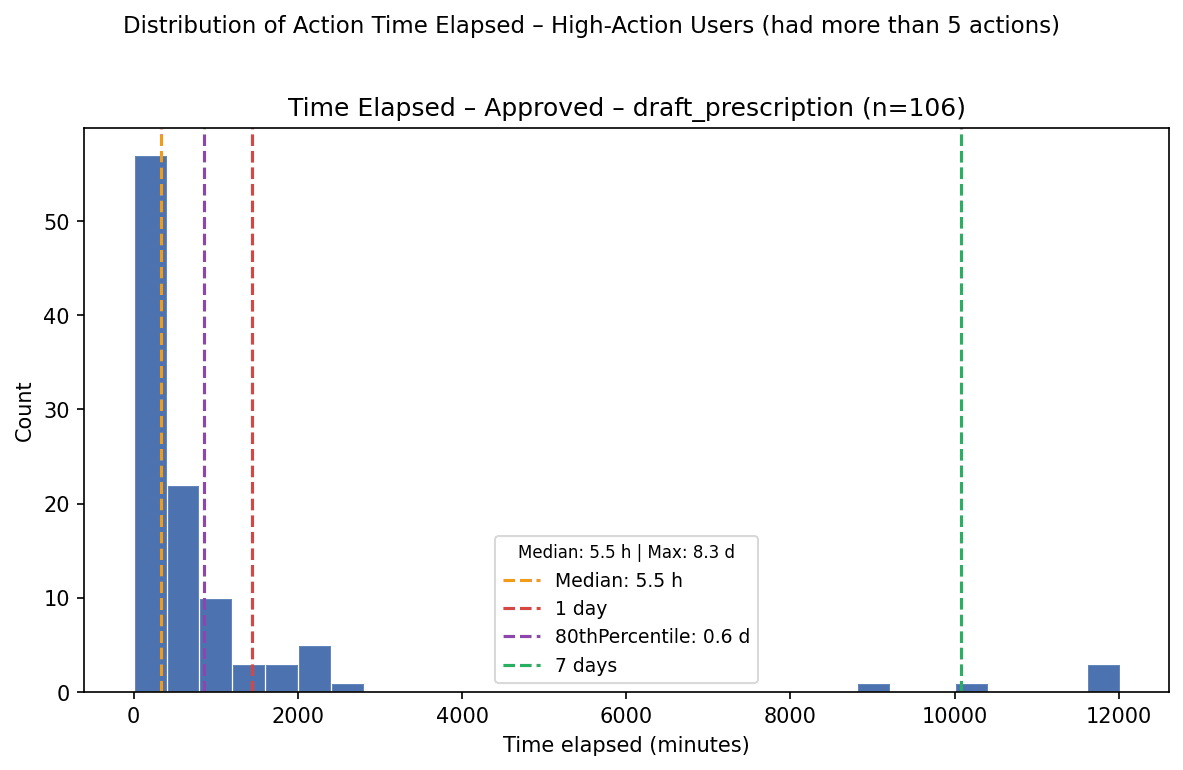
Prescriptions | 5.5 h | 14.2 h | 106 |
Prescriptions may resolve faster because medication decisions are often more urgent and more binary: once the clinician decides the prescription is appropriate, the action can move quickly. Lab orders may take longer because they often depend on additional context, administrative completeness, or coordination outside the immediate review surface.
Across action types, most approved actions resolved within roughly one day. This suggests that the Cortex-to-clinician workflow can support same-day or next-day review for many asynchronous care actions.
Interpretation
This analysis provides early evidence that clinicians can collaborate with a clinical agent to coordinate asynchronous primary care actions.
The strongest signal is not the number of actions Cortex generated. Generating more suggested work is easy. The stronger signal is that clinicians rarely rejected actions they reviewed, and among finalized non-pending decisions, almost all were approved.
Three findings are especially important.
First, clinician agreement is a useful real-world evaluation signal for clinical AI systems. Benchmarks can measure medical knowledge, but clinician decisions measure whether AI-generated outputs are acceptable inside a care workflow. This distinction is consistent with recent clinical AI literature emphasizing richer workflow-oriented evaluation rather than relying only on benchmark performance or final-answer accuracy.[4,5]
Second, different action types require different levels of oversight. Follow-up messages appear comparatively reliable. Lab orders benefit from iterative refinement. Prescriptions require stricter guardrails because they depend on more clinical, regulatory, and contextual prerequisites.
Third, pending actions are a major operational bottleneck. The rejection rate is low, but nearly one-third of proposed actions remained unresolved. Understanding why clinicians leave actions pending may be more important than further reducing the already-low rejection rate.
Limitations
This analysis has several limitations.
First, it was observational and conducted within a single care model at Lotus AI. The findings may not generalize to other clinical settings, specialties, patient populations, or review workflows.
Second, clinician approval is not equivalent to independent clinical optimality. An approved action may be reasonable without being the best possible action. Future work should compare proposed actions against blinded clinical review and patient outcomes.
Third, pending actions complicate interpretation. Some pending actions may eventually be approved or rejected. Others may have become irrelevant, been handled elsewhere, or remained unresolved because of workflow constraints.
Fourth, execution success depends on many factors beyond the proposed action, including patient behavior, insurance, pharmacy systems, lab availability, demographic completeness, and operational processes.
Fifth, conversation-topic classification was performed using LLM-based methods and should be interpreted as an approximate characterization of user activity rather than a definitive clinical taxonomy.
Finally, this analysis evaluates clinician agreement with suggested care actions. It does not establish that Cortex improved patient outcomes, reduced adverse events, lowered cost, or decreased clinician workload.
Future work
Future evaluations should examine whether clinician-supervised AI proposals improve measurable care outcomes, shorten time to treatment, reduce clinician burden, increase follow-up completion, or improve patient experience.
Additional analyses should characterize why actions remain pending, distinguish minor from major revisions, and test whether stronger prerequisite checks reduce prescription and lab-order rejections. For example, Cortex could more explicitly identify when an action requires recent vitals, confirmatory labs, specialist input, in-person evaluation, or updated insurance before presenting it for approval.
Longitudinal evaluation will also be important. A clinical agent should not only produce an acceptable next action. It should maintain a coherent understanding of the patient’s active problems, revise plans when new information arrives, and avoid duplicative or stale actions as care progresses.
Conclusion
In this analysis of 1,678 AI-suggested care actions across 244 patients, clinicians approved most proposed actions and rarely rejected them. Among actions with final non-pending decisions, 98% were approved.
The findings suggest that a clinician-supervised AI agent can help prepare actionable follow-up messages, lab orders, and prescriptions within an asynchronous primary care workflow. They also show that performance differs by task: follow-up messages are comparatively reliable, lab orders appear to benefit from revision, and prescriptions require the most cautious oversight.
For clinical AI systems, real-world evaluation should include not only what models say, but what clinicians are willing to do with their outputs.
Sources
[1] U.S. Health Resources and Services Administration. “Asynchronous direct-to-consumer telehealth.” Telehealth.HHS.gov. https://telehealth.hhs.gov/providers/best-practice-guides/direct-to-consumer/asynchronous-direct-to-consumer-telehealth
[2] Patel SY, Mehrotra A, Huskamp HA, Uscher-Pines L, Ganguli I, Barnett ML. “Trends in outpatient care delivery and telemedicine during the COVID-19 pandemic in the US.” JAMA Internal Medicine. Definition and review context also summarized in: “Asynchronous Telemedicine: A Systematic Review.” Journal of Medical Internet Research / PMC. https://pmc.ncbi.nlm.nih.gov/articles/PMC10739789/
[3] AMN Healthcare. “2025 Survey of Physician Appointment Wait Times.” 2025. https://www.amnhealthcare.com/siteassets/amn-insights/physician/ps-2025-physician-appt-wait-times—wp-v6.pdf
[4] Goh E, Gallo R, Hom J, et al. “Large Language Model Influence on Diagnostic Reasoning: A Randomized Clinical Trial.” JAMA Network Open. 2024;7(10):e2440969. https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2825395
[5] Rao AS, et al. “Large Language Model Performance and Clinical Reasoning.” JAMA Network Open. 2026. https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2847679

KJ Dhaliwal
Founder & CEO

Zekka Nelson
Founder & CTO

Aidan Cole
Founding Chief Growth Officer (ex-Underlining, ex-Dil Mil)

Lukas Nel
Founding AI Engineer (CS @ Yale)
Daniel Fleury
Founding Technical Staff (CS & Cognitive Science @ Johns Hopkins)

Nicholas Stark, MD
VP Clinical Strategy (MD @ Georgetown, EM @ UCSF)

Aravind Mani, MD
VP of Medical Affairs (MD @ Stanford, Internal Medicine @ UCLA)

Varinderjit Kaur, MD
Head of Clinical Operations (Internal Medicine @ USF Morsani, UCSF Hyde)

Zili Shen, PhD
Member of Technical Staff (Yale PhD)

Marcell Borhi
Research Engineer (CS @ IU, Biostatistics Graduate @ Berkeley)

Merrick Poon
Senior iOS Engineer (ex-Tinder)




