
Published by
Modern U.S. health systems actively contribute to a growing medication data quality problem. A decade-long evaluation of EHRs across 2,314 U.S. hospitals found that they fail to meaningfully improve medication safety — in 2018, one in three potentially harmful medication errors still went undetected.
The medication data that clinicians and automated systems depend on is, in many cases, incomplete, contradictory, or wrong.
This problem persists even when data passes through health information exchange (HIE) vendors with robust preprocessing protocols. Raw medication data still arrives distorted, duplicated, and incomplete. One study found that 60% of ambulatory patients in a VA system with fully integrated EHR–pharmacy linkage had at least one medication discrepancy: commissions, omissions, duplications, and dosage alterations. A separate report highlights a 74% discrepancy rate among outpatient clinic patients. These results align with what we observe firsthand in user conversations with Lotus AI: EHR data alone, even from best-effort HIE vendors, rarely produces an accurate medication list.
For any system that ingests FHIR medication data and enables large language models (LLMs) to interact with it, these problems are immediately tangible. Pull any patient profile and you'll find Zofran 4MG Oral Tablet, Zofran, ondansetron HCl, and ondansetron ODT listed side by side — four entries for the same drug, none agreeing on how to name it. Multiply that across resource types (MedicationRequest, MedicationStatement, MedicationDispense, MedicationAdministration), add inconsistent clinical codes, outdated status values, and timestamps ranging from `"1900-01-01"` to `"9999-12-31"`, and the scope of the problem compounds quickly.
Even the most capable reasoning models cannot reconcile data when contamination and self-contradiction saturate their context window. At Lotus Health AI, we address this directly.
We built a dedicated preprocessing pipeline that raises the floor on data quality before it touches reasoning models.
After analyzing an exhaustive distribution of anomalies in patient data, we engineered methods to normalize medication names, clean up timestamps, validate statuses, and deduplicate records across resource types.
Highlights
Measurable noise reduction
Across a random sample of over 36,000 medication records spanning ~400 patients, more than half of all medication names appeared multiple times, with some exceeding 200 occurrences. Our pipeline reduced the worst-case record count per patient from 2,363 to 271 and halved the average, eliminating extreme redundancy while preserving the clinical breadth of each patient's medication profile.
Precision where it matters most
Incorrectly grouping two clinically distinct medications is a patient safety failure. Our pipeline enforces strict boundaries: medications that appear similar but differ in clinical function remain separate. This way, downstream AI reconciliation systems receive deduplicated, high-fidelity input and spends its capacity on genuine clinical reasoning rather than untangling conflicting data.
Full traceability
Every decision the pipeline makes is auditable. When AI operates in clinical workflows, the data engineering upstream of the model must be as defensible as the model itself. Clinicians and engineers can trace any output back through each stage and understand exactly why a record was normalized, grouped, or selected.
Input: FHIR Medication Resources
We primarily process HL7 FHIR R4 formatted data. Medication information is distributed across four resource types, each capturing a different stage of the prescribing and administration lifecycle (see the FHIR R4 specification for full definitions):
Resource Type | What It Represents |
|---|---|
| A prescription order with instructions for administration |
| A patient or clinician's report of medication use |
| A pharmacy supply record |
| A documented event of medication being administrated |
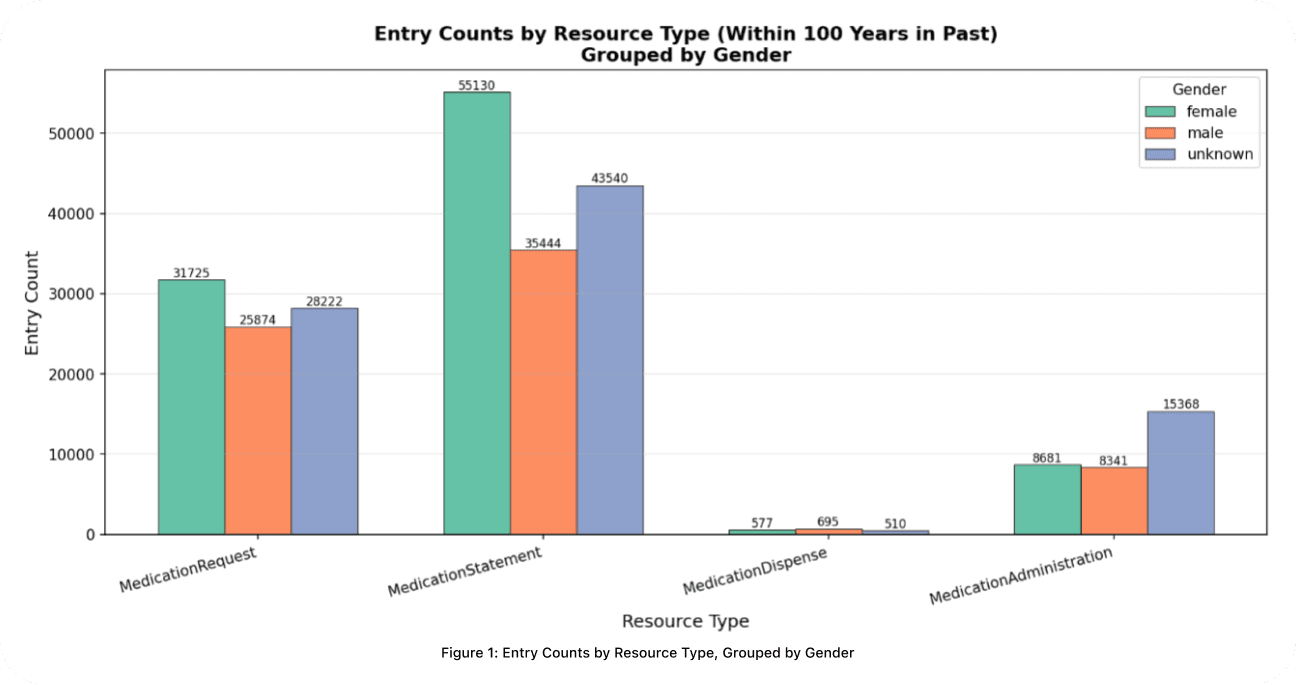
In a random sample of ~400 patients (Fig 1.), prescriptive and historical records significantly outnumber fulfillment documentation. Female patients represent the largest explicitly identified demographic in prescriptive categories, but the completeness of gender data remains a notable gap. "Unknown" entries outnumber both male and female patients in `MedicationAdministration`, indicating systematic shortfalls in demographic capture during clinical documentation.
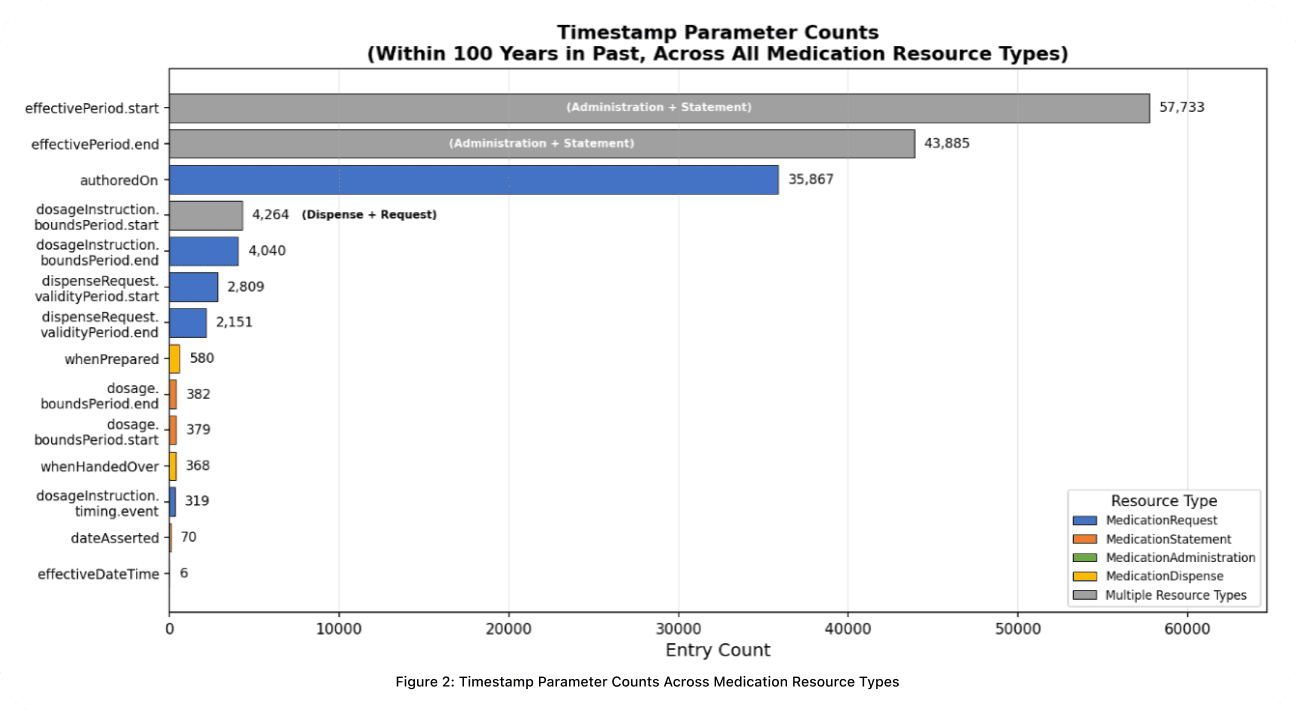
Timestamp completeness varies substantially across resource types (Fig 2.). effectivePeriod.start and effectivePeriod.end are the most frequently populated fields, appearing in both MedicationStatement and MedicationAdministration. For prescription-derived records, authoredOn is the most reliably present, followed by dosage timing and dispense timestamps. The pattern is consistent: historical and prescriptive time windows are better documented than precise dispensing and administration events.
A single real-world prescription can generate entries across all four resource types. In practice, varying documentation standards across care providers and differences in how EHR vendors populate these resources mean that the same medication frequently appears under different names and codes, with ambiguous timestamps and inconsistent status values. Our pipeline is designed to identify and resolve exactly this heterogeneity.
Deduplication at Scale
A single medication can appear dozens of times across a patient's FHIR data: as a prescription, a pharmacy dispense record, a clinician's statement, and more. Without rigorous preprocessing, a reconciler inherits all of that redundancy.
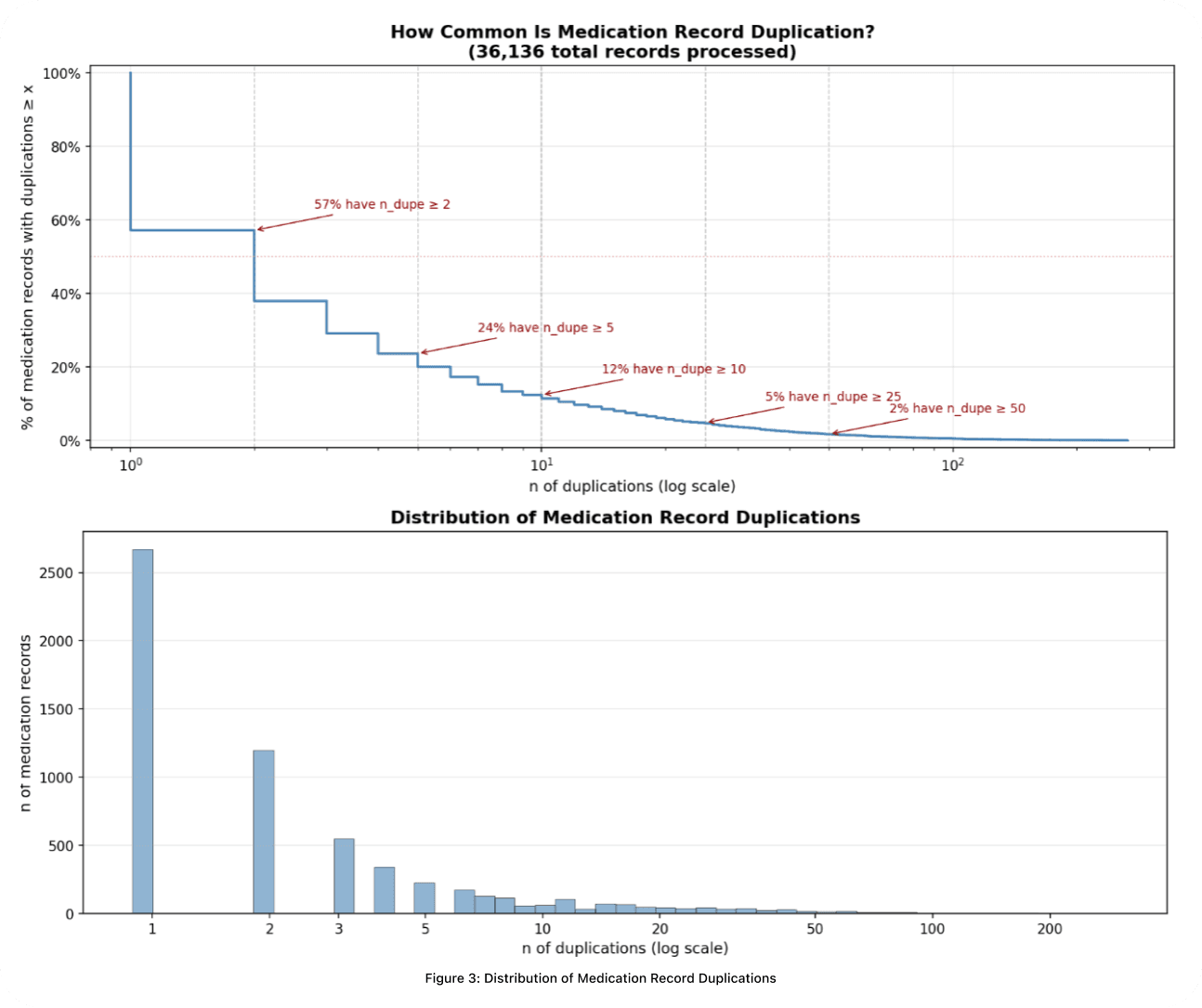
Across over 36,000 medication records (Fig 3.), duplication is overwhelmingly the norm, even after initial preprocessing. In the top panel, more than half of records referring to the same medication appear two or more times, and 24% have at least five duplicates. The bottom panel reveals the long tail: edge cases stretch beyond 200 appearances. Without dedicated engineering, a reconciler wastes capacity re-evaluating the same drug dozens of times regardless of how capable the underlying model is.
Our pipeline processes every instance across all resource types and distills them into a single, trustworthy record per distinct medication representing the patient's most current medication use.
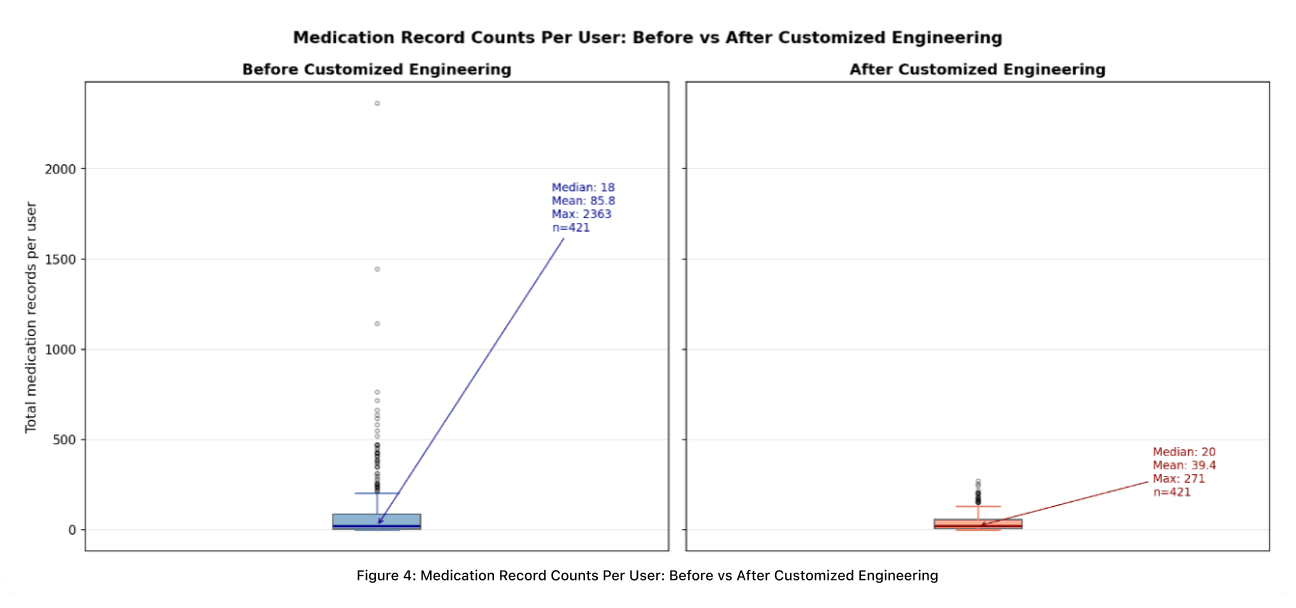
The impact is measurable (Fig 4.). Before the pipeline, medication record counts per patient vary wildly: a median of 18 but outliers as high as 2,363, pushing the mean to nearly 86. After processing, the maximum drops from 2,363 to 271 and the mean falls from 85.8 to 39.4. The extreme redundancy is eliminated while the meaningful clinical breadth of each patient's medication profile is preserved. Below are the key stages that make this possible.
Name Normalization
Medication names in EHR data are dramatically inconsistent. The same drug may appear as a brand name, a generic name, a name decorated with salt forms and dosage units, or some combination of all three. Grouping by raw name alone guarantees overcounting. Our pipeline strips noise (dosage forms, route descriptors, salt suffixes), maps brand names to generic equivalents, and distinguishes cases where a term like *calcium* is the active ingredient versus a chemical suffix. The result is a canonical identity for each medication based purely on its active ingredients.
Temporal and Status Validation
Each FHIR resource type stores dates in different fields with different purposes and varying precision. A single MedicationRequest may carry dates in its dosage timing, dispensing validity window, and authoring timestamp, each with different reliability. Our pipeline extracts dates from the correct fields per resource type, ranks sources by trust, and handles partial dates, leap seconds, and inconsistent timezone representations.
FHIR status fields compound the problem. A prescription marked "active" may have been authored years ago, making it effectively inactive. We normalize raw status values into a simplified classification, then cross-check them against extracted timestamps. A record claiming active status must have temporal evidence to support it. Drawing on regulatory context (such as how long a prescription remains legally valid), we reclassify records whose timestamps contradict their claimed status and flag ambiguous cases for downstream review.
Record Grouping
This is the most critical operation: determining which records refer to the *same* medication so they can be consolidated. A patient with 10 raw FHIR entries for atorvastatin should produce one record, not ten. Simple string matching is too brittle. We use a multi-signal approach that considers active-ingredient identity, clinical code agreement, and standardized terminology resolution. The approach is transitive: if record A matches B on one dimension and B matches C on another, all three are grouped, enabling robust deduplication without sacrificing precision.
Representative Selection
Each medication group may contain many candidate records. We select the representative that best captures the current truth about that medication. Rather than collapsing everything into a single score, we evaluate candidates across multiple clinical dimensions in order of priority: status reliability, temporal relevance, and data source authority. This keeps the selection transparent and fully traceable.
Output
Post-processing, the pipeline produces clean, structured representations of medication data that downstream reasoning models can actually work with: one record per distinct medication, each with a normalized name, a validated status, reliable date ranges, and full provenance.
One class of these downstream models are asynchronous agents we call *Reconcilers*: systems equipped with data science toolkits that ingest both patient-reported data and hospital-reported records in real time. Reconcilers compute diffs against the preprocessed tables to continuously produce and refine the richest possible ground truth of a patient's medication profile. The cleaner the input they receive, the more their capacity is spent on genuine clinical reasoning rather than resolving upstream noise.
Why This Matters
This work is not just a data engineering improvement, but rather, has direct consequences for every participant in the care loop. When medication data is inaccurate, patients will inevitably receive inaccurate interpretations from AI models in conversations about their medications. That same data forms the ground truth that clinicians in our system rely on for clinical decision-making. Data quality failures propagate in both directions.
At Lotus, we treat continuity of data quality and management as a precondition for positive care outcomes. A core design principle we hold: *could a human meaningfully reason over this data?* LLMs operate in high-dimensional embedding and token spaces, but the clinical judgments they support must remain interpretable and defensible at every stage. If the data wouldn't survive human scrutiny, it shouldn't reach the model.
Looking ahead, we are extending this pipeline beyond medications to reconcile and compute structured representations across all FHIR resource types, alongside weighted clinical significance scores that prioritize the records most relevant to active patient care. Ensuring data quality for patients, for Lotus, and for the clinicians partnering in our system is what makes care more efficacious and safe.

KJ Dhaliwal
Founder & CEO

Zekka Nelson
Founder & CTO

Aidan Cole
Founding Chief Growth Officer (ex-Underlining, ex-Dil Mil)

Lukas Nel
Founding AI Engineer (CS @ Yale)

Daniel Fleury
Founding Technical Staff (CS & Cognitive Science @ Johns Hopkins)

Nicholas Stark, MD
VP of Clinical Strategy (MD @ Georgetown, EM @ UCSF)

Aravind Mani, MD
VP of Medical Affairs (MD @ Stanford, Internal Medicine @ UCLA)

Varinderjit Kaur, MD
Head of Clinical Operations (Internal Medicine @ USF Morsani, UCSF Hyde)

Zili Shen, PhD
Member of Technical Staff (Yale PhD)

Marcell Borhi
Research Engineer (CS @ IU, Biostatistics Graduate @ Berkeley)

Merrick Poon
Senior iOS Engineer (ex-Tinder)




